
AI
Phase 1:扫货
机器学习基本框架
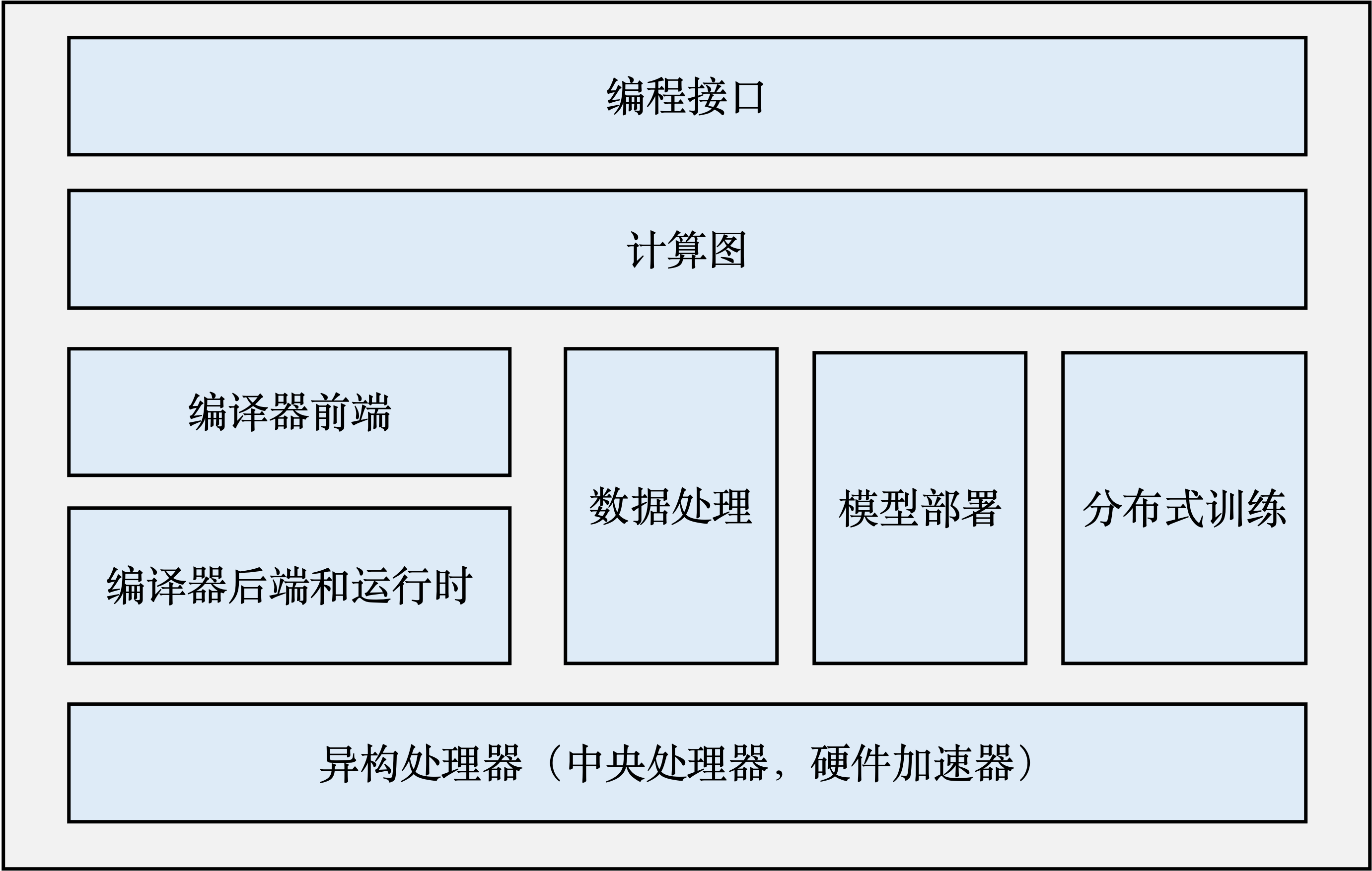
- 计算图:定义了用户的机器学习程序,由表达计算操作的算子节点(Operator Node),以及表达算子之间计算依赖的边(Edge)构成
- 编译器:用来将程序转换为计算图,并将计算图转换为硬件可以执行的程序。
- 编译器前端:关键功能包括实现中间表示、自动微分、类型推导和静态分析等。利用这些功能对程序进行分析和优化
- 编译器后端和运行时:实现针对不同底层硬件的优化。包括分析硬件的L2/L3缓存大小和指令流水线长度,优化算子的选择或者调度顺序。
- 异构处理器:机器学习应用的执行通常由CPU与硬件加速器(GPU、NPU等)共同完成,其中非矩阵运算操作通常由CPU完成,矩阵运算和部分算子由硬件加速器进行运算
- 分布式训练: 机器学习模型的训练往往需要分布式的计算节点并行完成。其中,常见的并行训练方法包括数据并行、模型并行、混合并行和流水线并行。
机器学习编程库
- TensorFlow:相比于传统的Torch,TensorFlow提出前后端分离相对独立的设计,利用高层次编程语言Python作为面向用户的主要前端语言,而利用C和C++实现高性能后端。大量基于Python的前端API确保了TensorFlow可以被大量的数据科学家和机器学习科学家接受,同时帮助TensorFlow能够快速融入Python为主导的大数据生态(大量的大数据开发库如Numpy、Pandas、SciPy、Matplotlib和PySpark)
- MindSpore:在继承了TensorFlow、PyTorch的Python和C/C++的混合接口的基础上,进一步拓展了机器学习编程模型从而可以高效支持多种AI后端芯片(如华为Ascend、英伟达GPU和ARM芯片),实现了机器学习应用在海量异构设备上的快速部署。同时,超大型数据集和超大型深度神经网络崛起让分布式执行成为了机器学习编程框架的核心设计需求。为了实现分布式执行,TensorFlow和PyTorch的使用者需要花费大量代码来将数据集和神经网络分配到分布式节点上,而大量的AI开发人员并不具有分布式编程的能力。因此MindSpore进一步完善了机器学习框架的分布式编程模型的能力,从而让单节点的MindSpore程序可以无缝地运行在海量节点上。
C/C++编程接口
由于Python的解释器是由C实现的,因此在Python中可以实现对于C和C++函数的调用。现代机器学习框架(包括TensorFlow,PyTorch和MindSpore)主要依赖Pybind11来将底层的大量C和C++函数自动生成对应的Python函数,这一过程一般被称为Python绑定(Binding)。主要由以下几个步骤:
- 注册算子原语
- GPU算子开发,调用CUDA Kernel函数实现gpu加速
- GPU算子注册
友情链接:Pybind11
计算图
设计初衷
现代机器学习模型的拓扑结构日益复杂,需要机器学习框架能够对模型算子的执行依赖关系、梯度计算以及训练参数进行快速高效的分析,便于优化模型结构、制定调度执行策略以及实现自动化梯度计算,从而提高机器学习框架训练复杂模型的效率。因此,机器学习系统设计者需要一个通用的数据结构来理解、表达和执行机器学习模型。
基本构成
计算图由基本数据结构张量(Tensor)和基本运算单元算子构成。通常使用节点表示算子,节点间的有向边表示张量状态,同时也能描述出计算间的依赖关系。
算子
按照功能可以将算子分类为张量操作算子、神经网络算子、数据流算子和控制流算子等。
- 张量操作算子:包括结构操作(改变形状、维度、张量合并等)与数学运算操作(矩阵乘法、行列式特征值计算等)
- 神经网络算子:包括特征提取、激活函数、损失函数、优化算法等
- 数据流算子:包括数据预处理(normalize,shuffle)与数据载入(分批载入、预载入等)
- 控制流算子:分为机器学习框架本身提供的控制流操作符和前端语言控制流操作符。
计算依赖
在计算图中,算子之间存在依赖关系,而这种依赖关系影响了算子的执行顺序与并行情况。
控制流
目前主流的机器学习框架中通常使用两种方式来提供控制流:前端语言控制流,即Python自带的控制流语句,但由于机器学习框架的数据运行在后端,这会造成控制流与数据流分离,计算图不能完整运行在后端,称为“图外方法”;机器学习框架控制原语,即机器学习框架在内部设计的低级别细粒度的控制原语运算符,这些操作符能够执行在计算硬件上,可将整体计算图在后端运算,称为“图内方法”
计算图生成
在机器学习框架中可以生成静态图和动态图两种计算图。
静态生成
机器学习框架将模型编译为可被后端计算硬件调用执行的固定代码文本,这些文本就是静态的计算图。之后如果使用静态计算图进行模型训练或推理,就无需再次编译前端语言模型。
动态生成
动态计算图采用解析式的执行方式,其核心特点是编译与执行同时发生。动态图采用前端语言自身的解释器对代码进行解析,利用机器学习框架本身的算子分发功能,算子会即刻执行并输出结果。
由于机器学习框架无法通过动态生成获取完整的模型结构,因此动态图模式下难以进行模型优化以提高计算效率。
动态图转静态图
- 基于追踪转换:以动态图模式执行并记录调度的算子,构建和保存为静态图模型。追踪技术只是记录第一次执行动态图时调度的算子,但若是模型中存在依赖于中间结果的条件分支控制流,只能追踪到根据第一次执行时触发的分支。
- 基于源码转换:分析前端代码来将动态图代码自动转写为静态图代码,并在底层自动帮用户使用静态图执行器运行。其核心步骤是,将源码转换为抽象语法树,之后将抽象语法树转写为静态图
计算图调度
总的来说,计算图的调度分为两个步骤:
- 根据拓扑排序算法,将计算图进行拓扑排序以得到线性的算子调度序列
- 将序列中的算子分配到指令流进行运算,尽可能将序列中的算子并行执行
串行 并行
对于调度序列中的任务,我们可以以串行和并行两种方式进行调度。
如果两算子之间的依赖关系是直接依赖或间接依赖,那么只能以串行的方式进行调度。如果两算子间相互独立,那么可以并行调度。
并行包括算子并行、模型并行以及数据并行:
- 算子并行
不仅可以在相互独立的算子间实现,同时也可以将单个算子合理的切分为相互独立的多个子操作,进一步提高并行性。
- 模型并行
模型并行可分为张量并行和流水并行
张量并行,指将模型的张量操作分解成多个子张量操作,并且在不同的设备上并行执行这些操作,这样能够将大模型的计算负载分布到多个设备上。流水并行指,将模型的不同层划分成多个阶段,并且每个阶段在不同的设备上并行执行,每个设备负责计算模型的一部分,并将计算结果传递给下一个设备,形成一个计算流水线。
- 数据并行
数据并行按照模型在设备之间的通信程度可分为三种:DP, DDP, FSDP
- 数据并行(Data parallelism),是最简单的一种并行技术,将大规模数据集分成多批,每批发送到不同的设备上并行处理,之后通过
all_reduce在计算设备上更新模型参数。每个计算设备拥有完整的模型副本。 - 分布式数据并行(Distribution Data Parallel),它允许模型在多个计算节点上进行并行训练,每个节点都有自己的本地模型副本和本地数据。每个节点上的模型副本执行前向和后向传播计算,并计算梯度。然后,这些梯度在不同的节点之间进行通信和平均,以便所有节点都可以使用全局梯度来更新其本地模型参数。
- Fully Sharded Data Parallelism (FSDP) 技术是 DP 和 DDP 技术的结合版本,这种技术的核心思想是将神经网络的权重参数以及梯度信息进行分片(shard),并将这些分片分配到不同的设备或者计算节点上进行并行处理。
AI编译器
AI编译器前端技术
编译器前端的主要任务是将源代码解析成计算图IR,并对其进行设备无关的优化。
中间表示(IR)
- 基本概念:
中间表示是编译器用于表示源代码的数据结构或代码,是程序编译过程中介于源语言和目标语言之间的程序表示。在编译过程中,中间表示必须具备足够的表达力,在不丢失信息的情况下准确表达源代码,并且充分考虑从源代码到目标代码编译的完备性、编译优化的易用性和性能。
引入中间表示后,可以直接在前端和后端之间增加优化流程
- 种类:
- 线性中间表示
被编译代码表示为操作的有序序列,对操作序列规定了一种清晰且实用的顺序
- 图中间表示
图中间表示将编译过程的信息保存在图中,算法通过图中的对象如节点、边、列表、树等来表述。包括抽象语法树、有向无环图等。
- 机器学习框架的中间表示
MLIR:
MLIR不是一种具体的中间表示定义,而是为中间表示提供一个统一的抽象表达和概念。开发者可以使用MLIR开发的一系列基础设施,来定义符合自己需求的中间表示, 因此我们可以把MLIR理解为“编译器的编译器”。由于各层中间表示都遵循统一的样式进行定义,所以各个层级的中间表示之间可以更加方便的进行转换, 提高了中间表示转换的效率。
自动微分
设计众多中间表示的核心目的之一就是服务于自动微分变换。
自动微分的思想是将计算机程序中的运算操作分解为一个有限的基本操作集合,且集合中基本操作的求导规则均为已知,在完成每一个基本操作的求导后,使用链式法则将结果组合得到整体程序的求导结果。
自动微分根据链式法则的不同组合顺序,可以分为前向模式(Forward Mode)和反向模式(Reverse Mode)。前向模式的自动微分指从输入方向开始计算梯度值,反向模式则从输出方向开始计算。对于一个带有
类型系统
Python语言是一门动态强类型的语言,但由于其解释执行的方式,运行速度往往较慢,若想要生成运行高效的后端代码,后端框架需要优化友好的静态强类型中间表示。因此,需要一种高效可靠的静态分析方法作为桥梁,将Python前端表示转换成等价的静态强类型中间表示,以此给用户同时带来高效的开发效率和运行效率。
静态分析
在设计好类型系统后,编译器需要使用静态分析系统来对中间表示进行静态检查与分析。语法解析模块(parser)将程序代码解析为抽象语法树(AST)并生成中间表示。此时的中间表示缺少类型系统中定义的抽象信息,因此引入静态分析模块,对中间表示进行处理分析,并且生成一个静态强类型的中间表示,用于后续的编译优化、自动并行以及自动微分等。
前端编译优化方法
编译优化器以“趟”(Pass)为单位组成。在编译优化中,优化操作的选择以及顺序对于编译的整体具有非常关键的作用。
常见的前端编译优化方法包括:无用代码消除,常量传播、常量折叠,公共子表达式消除。
前端是不感知具体后端硬件的,因此前端执行的全部都是与硬件无关的编译优化。
编译器后端和运行时
编译器后端的主要任务是对前端下发的IR进一步优化,使其贴合硬件,并为IR中的计算节点选择在硬件上执行的算子,然后为每个算子的输入输出分配硬件内存,最终生成一个可以在硬件上执行的任务序列。
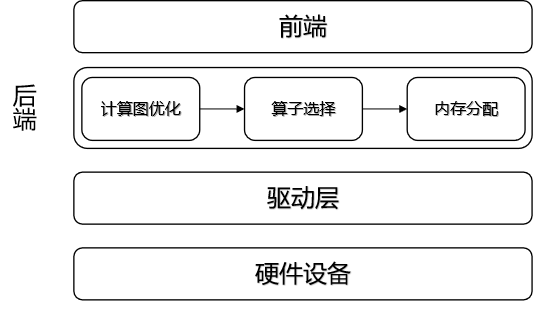
计算图优化
根据优化适用于所有硬件还是只适合特定硬件,可以分为通用硬件优化和特定硬件优化。
- 通用硬件优化
优化的核心是图的等价变换:在计算图中尝试匹配特定的子图结构,找到目标子图结构后,通过等价替换方式,将其替换成对硬件更友好的子图结构。
典型的优化方法是将将计算密集型算子与访存密集型算子进行融合,以提升IO效率。
基于自动算子生成技术,还可以实现更灵活、更极致的通用优化。例如图算融合通过“算子拆解、算子聚合、算子重建”三个主要阶段让计算图中的计算更密集,并进一步减少低效的内存访问。
- 特定硬件优化
常见的基于硬件的优化包括由于硬件指令的限制而做的优化,特定硬件存储格式导致的优化等。
算子选择
经过计算图优化后,需要对IR图上的每个节点进行算子选择,才能生成真正在设备上执行的算子序列。由于IR图上的节点可能有后端的很多算子与其对应,不同规格的算子在不同的情况下执行效率各不相同,在算子选择阶段的主要任务就是如何根据IR图中的信息在众多算子中选择出最合适的一个算子去目标设备上执行。
IR图上的每个节点都有一组算子与之对应。每个节点代表了用户代码的一个操作,现在对于这个操作还没有具体生成有关设备信息的细节描述,这些信息称为算子信息。算子信息主要包括:
- 针对不同特点的计算平台和不同的算子需要选择合适的数据排布
- 对于不同的硬件支持不同的计算精度,例如float32、float16和int32等。算子选择需要在所支持各种数据类型的算子中选择出用户所设定的数据类型最为相符的算子
- 支持设备类型
- 数据排布
在机器学习系统中常见的数据格式一般有两种,分别为NCHW类型和NHWC类型。其中N代表了数据输入的批大小,C代表了图像的通道,H和W分别代表图像输入的高和宽。对于一个多维矩阵,计算机需要将其平展为1维才能进行存储,这两种数据格式的区别就在于平展方式上。对于NCHW的数据是先取W轴方向数据,再取H轴方向数据,再取C轴方向,最后取N轴方向。类似的NHWC数据格式是先取C方向数据,再取W方向,然后是H方向,最后取N方向。
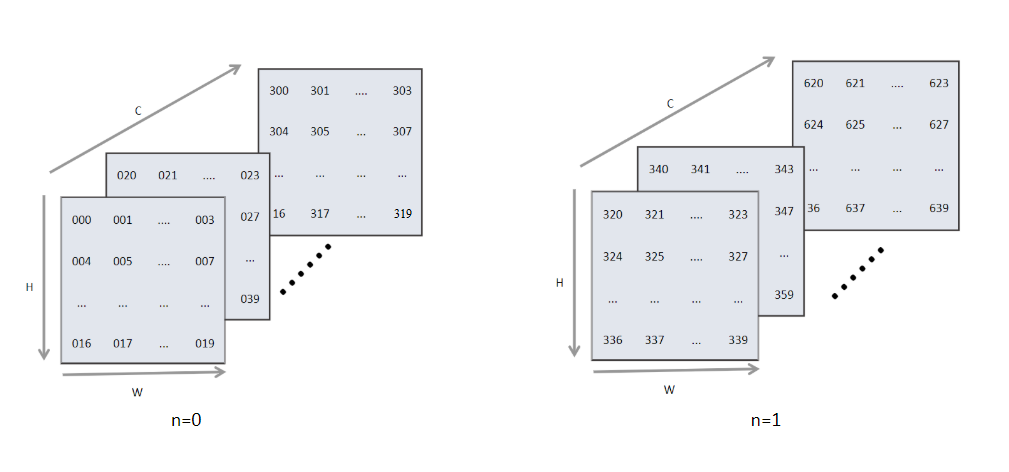
为了加速运算很多框架又引入了一些块布局格式来进行进一步的优化,这种优化可以使用一些硬件的加速指令,对数据进行搬移和运算。
- 数据精度
通常深度学习的系统,使用的是单精度(float32)表示。这种数据类型占用32位内存。还有一种精度较低的数据类型为半精度(float16),其内部占用了16位的内存。
- 算子信息库
一个硬件上支持的所有算子的集合定义为该硬件的算子信息库,算子选择过程就是从算子信息库中选择最合适算子的过程。
算子选择过程中,首先,要选择算子执行的硬件设备。之后选择数据精度,理想情况下应与用户指定的精度一致,但有时也需要为了匹配算的要求的精度进行升精度或降精度。算子的数据排布格式转换是一个比较耗时的操作,为了避免频繁的格式转换所带来的内存搬运开销,数据应该尽可能地以同样的格式在算子之间传递,算子和算子的衔接要尽可能少的出现数据排布格式不一致的现象。
内存分配
- 设备内存与主机内存
通常将与硬件加速器(如GPU、AI芯片等)相邻的内存称之为设备(Device)内存,而与CPU相邻的内存称之为主机(Host)内存。硬件加速器只能访问设备内存,CPU只能访问主机内存。
- 内存分配
在许多对性能要求严苛的计算场景中,由于所申请内存块的大小不定,频繁申请释放会降低性能。通常会使用内存池的方式去管理内存,先申请一定数量的内存块留作备用,当程序有内存申请需求时,直接从内存池中的内存块中申请。当程序释放该内存块时,内存池会进行回收并用作后续程序内存申请时使用。
- 内存复用
内存复用是指分析张量的生命周期,将生命周期结束的张量的设备内存释放回内存池并用于后续张量的内存分配。
- 内存分配优化手段
通常,内存分配都以单个张量的维度去分配的,导致每个张量的地址是离散的。有时可以为多个张量一起分配地址,成为“内存融合”。一般会为每个算子的输入和输出分配不同的地址,但有的算子的计算目的就是对数据进行更新,例如python中的*=或+=,这时可以为输入和输出分配同样的地址,以避免拷贝带来的时间开销,又节省了内存空间
计算调度与执行
经过算子选择与内存分配之后,计算任务可以通过运行时完成计算的调度与在硬件上的执行。根据是否将算子编译为计算图,计算的调度可以分为单算子调度与计算图调度两种方式。而根据硬件提供的能力差异,计算图的执行方式又可以分为逐算子下发执行的交互式执行以及将整个计算图或者部分子图一次性下发到硬件的下沉式执行两种模式。
- 计算图调度
在一个典型的异构计算环境中,主要存在CPU、GPU以及NPU等多种计算设备,因此一张计算图可以由运行在不同设备上的算子组成为异构计算图。
异构计算图能够被正确表达的首要条件是准确标识算子执行所在的设备。完成计算图中算子对应设备的标记以后,计算图已经准备好被调度与执行,根据硬件能力的差异,可以将异构计算图的执行分为三种模式,分别是逐算子交互式执行,整图下沉执行与子图下沉执行:
交互式执行主要针对CPU和GPU的场景,计算图中的算子按照输入和输出的依赖关系被逐个调度与执行
整图下沉执行主要是针对NPU芯片而言,这类芯片主要的优势是能够将整个神经网络的计算图一次性下发到设备上,无需借助主机的CPU能力而独立完成计算图中所有算子的调度与执行,减少了主机和芯片的交互次数,借助NPU的张量加速能力,提高了计算效率和性能
子图下沉执行是前面两种执行模式的结合,由于计算图自身表达的灵活性,对于复杂场景的计算图在NPU芯片上进行整图下沉执行的效率不一定能达到最优,因此可以将对于NPU芯片执行效率低下的部分分离出来,交给CPU或者GPU等执行效率更高的设备处理,而将部分更适合NPU计算的子图下沉到NPU进行计算,这样可以兼顾性能和灵活性两方面。
上述异构计算图可以实现两个目的,一个是异构硬件加速,将特定的计算放置到合适的硬件上执行;第二个是实现算子间的并发执行,在不同设备上的算子可以并发调用
- 交互式执行
对于非异构计算图来说,有两种安排执行顺序的方式:串行执行和并行执行。而一般来说,对于计算图的优化都是针对非异构计算图的,因此对于异构图,需要将其划分为多个非异构图,一般按照产生尽量少的子图的切分规则来切分,尽量将多的同一设备上的算子放在一张子图中。将一张异构计算图切分为多个子计算图后,执行方式一般分为子图拆分执行和子图合并执行。子图拆分执行指将切分后的多个子图分开执行,一个子图执行完后再执行另一个子图。子图合并执行指将切分后的多个子图合并成一个整体的DAG,避免子图切换产生的开销
- 下沉式执行
下沉式执行是通过专用芯片的SoC架构,将整个或部分计算图一次性调度到芯片上以完成全量数据的计算。下沉式执行由于避免了在计算过程中主机侧和设备侧的交互,因此可以获得更好的整体计算性能。然而下沉式执行也存在一些局限,例如在动态shape算子,复杂控制流等场景下会面临较大的技术挑战。
算子编译器
从目的上来说,算子编译器致力于提高算子的执行性能。从工程实现上来说,算子编译器的输入一般为Python等动态语言描述的张量计算,而输出一般为特定AI芯片上的可执行文件。
- 算子调度策略
算子编译器为了实现较好地优化加速,会根据现代计算机体系结构特点,将程序运行中的每个细小操作抽象为“调度策略”。
基于局部性概念,希望尽量把需要重复处理的数据放在固定的内存位置,且这一内存位置离处理器越近越好,以通过提升访存速度而进行性能提升。另外,把传统的串行计算任务按逻辑和数据依赖关系进行分割后,有机会得到多组互不相关的数据,并把他们同时计算。
通俗理解,调度策略指的是:在编译阶段根据目标硬件体系结构的特点而设计出的一整套通过提升局部性和并行性而使得编译出的可执行文件在运行时性能最优的算法。
- 子策略组合优化
算子编译器的一种优化思路是:将抽象出来的调度策略进行组合,拼接排布出一个复杂而高效的调度集合。
- 调度空间算法优化
算子编译器的另外一种优化思路是:通过对调度空间搜索/求解,自动生成对应算子调度。这类方法的好处是提升了算子编译的泛化能力,缺点是搜索空间过程会导致编译时间过长。
硬件加速器
架构
GPU的体系架构由两部分组成,分别是流处理阵列和存储器系统,两部分通过一个片上互联网络连接。流处理器阵列和存储器系统都可以单独扩展,规格可以根据产品的市场定位单独裁剪。
- 计算单元
以Nvidia GV100为例,其包含6个GPU处理集群GPC,每个GPC包含7个纹理处理集群TPC,每个TPC包含2个流多处理器SM。每个SM包含64个32位浮点运算单元、64个32位整数运算单元、32个64位浮点运算单元、8个张量计算核心、4个纹理单元。
- 存储单元
与CPU类似,GPU提供了不同层次的若干区域供程序员存放数据,每块区域的内存都有自己的最大带宽以及延迟。
寄存器文件:片上最快的存储器,GPU的每个SM(流多处理器)有上万个寄存器。
共享内存:是用户可控的一级缓存,每个SM有128K一级缓存。访存延迟仅几十个时钟周期,带宽高达1.5TB/s。
全局内存:GPU与CPU都可以对它进行读写操作。是GPU中容量最大的,可达32GB甚至更高,但访存延迟也最大,有上百时钟周期
- 计算单元
标量计算单元:一次计算一个标量元素
一维向量计算单元:一次可以完成多个元素的计算,与传统的CPU和GPU架构中单指令多数据(SIMD)相似
二维向量计算单元:一次运算可以完成一个矩阵与向量的内积,或向量的外积。
三维向量计算单元:一次完成一个矩阵的乘法,专为神经网络应用设计的计算单元
GPU计算单元主要由标量计算单元和三维计算单元组成
GPU线程分级
数据规模指为了完成计算,需要从内存中读取或写入的数据量;计算规模指所需的计算操作次数;算数强度指“每字节的数据访问量,能支持多少次计算”,其计算公式为
总的来说,计算模式有以下三种
- Element-wise(逐元素):每个输出数据只依赖于一个输入数据
数据规模与计算规模均为
- Local(局部):每个输出数据依赖于其附近的一小组输入数据
数据规模与计算规模均为
- All to All(全对全):每个输出数据都依赖于所有的输入数据
为了计算
而现代AI的核心运算是大量的矩阵乘法和卷积,这两种运算都属于All to All模式。
SM
流式多处理器(SM)是GPU的核心,GPU架构就是围绕SM搭建的,通过复制这种结构来实现GPU的硬件并行。
SM中包含:CUDA核心,共享/一级内存,寄存器文件,加载/存储单元,线程束调度器
线程束(Warp)是SM中的基本执行单元,当一个核函数被启动时,grid中的多个block被分配到可用的SM上,SM又将block分为warp,通常每个warp包含32个线程。在一个warp中,所有线程都按照SIMT的方式执行,每一步执行相同的指令,但是处理的数据为私有的数据。单指令多线程(SIMT)指将相同的指令广播给多个执行单元,但某些线程可以选择不执行。SIMT中每个线程有自己的PC,有自己的寄存器状态,有自己的独立执行路径,这样便保证不同线程之间的独立性。
Tensor Core
在英伟达的通用 GPU 架构中,主要存在三种核心类型:CUDA Core、Tensor Core 以及 RT Core。其中,Tensor Core是针对深度学习和 AI 工作负载而设计的专用核心。
- 计算原理
Tensor Core 采用融合乘法加法(FMA)的方式来高效地处理计算任务。每个 Tensor Core 每周期能执行 4x4x4 GEMM(general matrix multiply)。以 4×4矩阵计算为例,在计算
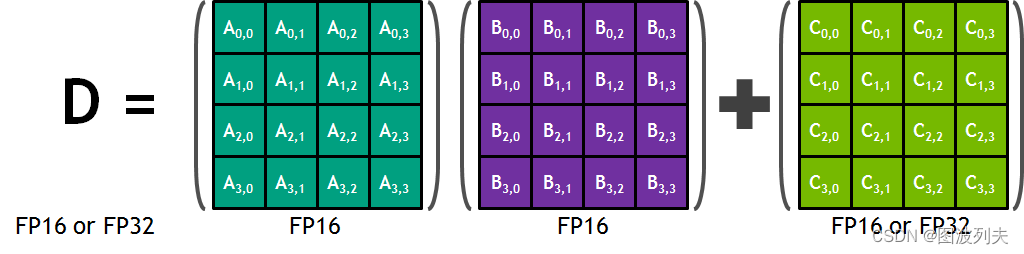
现在我们将计算简化为两个4×4矩阵乘法
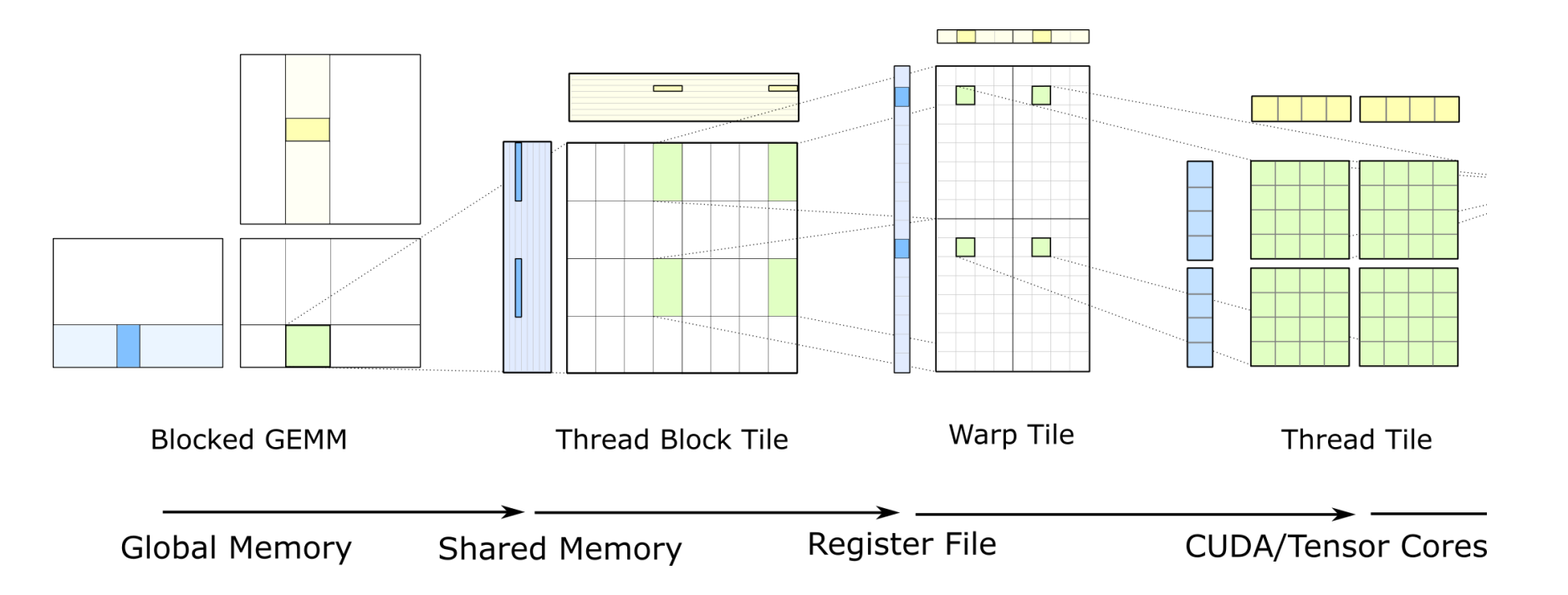
在编程时,我们能控制的最细粒度就是Warp,CUDA 通过 CUDA C++ WMMA API 向外提供了 Tensor Core 在 Warp 级别上的计算操作支持。
- Title: AI
- Author: OWPETER
- Created at : 2025-07-18 09:59:45
- Updated at : 2025-07-23 11:20:45
- Link: https://owpeter.github.io/2025/07/18/ML/machine-learning/
- License: This work is licensed under CC BY-NC-SA 4.0.