
CUDA
CUDA编程模型概述
CUDA编程结构
在异构环境中,CPU与GPU通常通过PCIe相互通信,在CUDA编程中,需要对这二者进行区分:
- 主机(Host):CPU及其内存
- 设备(Device):GPU及其内存
内存管理
我们知道c语言标准库提供了malloc,memcpy等函数对内存进行操作,这些函数只能操作Host的内存。如果想要操作设备上的内存,需要使用CUDA提供的API。
对于执行内存拷贝的cudaMemcpy函数,其函数定义为
1 | cudaError_t cudaMemcpy(void * dst,const void * src,size_t count, cudaMemcpyKind kind) |
cudaMemcpyKind是一个枚举类型,有cudaMemcpyHostToHost,cudaMemcpyHostToDevice,cudaMemcpyDeviceToHost,cudaMemcpyDeviceToDevice,能够看出是用来控制数据传输方向的
线程管理
CUDA是按照grid -> block -> thread的层次组织线程的。一个grid对应一次内核函数的调用,其中包含了多个block,每个block在物理上被调度到一个GPU的SM上执行,其中又包含了多个thread。
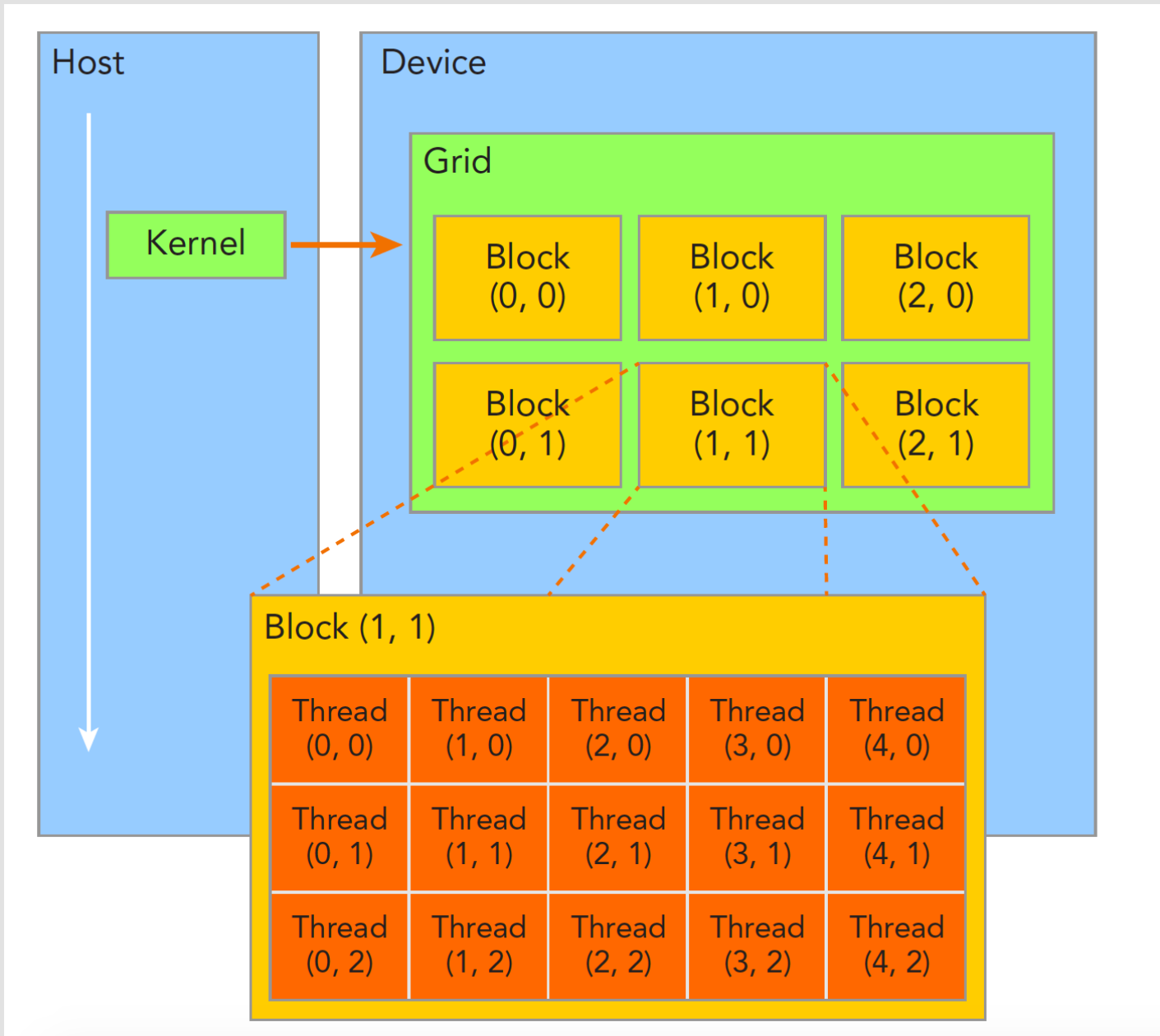
在核函数内,我们可以通过threadIdx和blockIdx这两个参数确定当前线程的编号,他们的含义分别是“线程在当前块中的index”和“块在当前grid中的index”。这两个参数定义在device_launch_parameters.h中:
1 | uint3 __device_builtin__ __STORAGE__ threadIdx; |
其中uint3是一个包含了三个unsigned int的结构体,包含x,y,z三个字段
但只知道两个index是不够的,还需要知道一个block中到底有多少个thread。通过blockDim可以获得此信息。blockDim的定义如下:
1 | dim3 __device_builtin__ __STORAGE__ blockDim; |
其中dim3是基于uint3定义的数据结构,也包含x,y,z三个字段。
这样,我们就可以计算线程编号了:
1 | int i=blockIdx.x*blockDim.x+threadIdx.x; |
线程管理2
上文介绍了一维网格如何确定线程全局index,这里介绍二维网格。
其实线程在二维网格中每一维的全局index的求法是一样的,并且也和一维的求法一样:
1 | ix = threadIdx.x + blockDim.x * blockIdx.x; |
获得线程全局index的目的是让不同的线程访问不同位置的内存,但数据在内存中的排布是连续的,也就说是一维的,因此我们需要将二维的ix,iy转换成idx
1 | idx = ix + iy * nx; |
其中nx是矩阵中一行元素的个数。
不过经过我的实验,在计算二维矩阵时把块中线程按一维安排似乎完全没有问题。
核函数
调用
核函数就是由设备上多个线程运行的代码,也就是你GPU要干的最核心的活。
在main函数中用以下代码调用核函数:
1 | kernel_name<<<grid,block>>>(argument list); |
这里的grid和block的物理意义又和上文介绍概念时的物理意义不太一样。这里的grid指一个grid里包含多少个block,block指一个block中包含多少个thread。
当核函数启动后,控制权马上交回到主机,如果想要主机等待设备端执行可以用cudaDeviceSynchronize()。当然也可以不显示的进行同步,例如可以调用cudaMemcpy(..., cudaMemcpyDeviceToHost)实现同步。
定义
在定义核函数时,必须加上限定符。
| 限定符 | 执行 | 调用 | 备注 |
|---|---|---|---|
__global__ |
设备端执行 | 可以从主机端调用也可以从计算能力3以上的设备端调用 | 必须有一个void的返回类型 |
__device__ |
设备端执行 | 设备端调用 | |
__host__ |
主机端执行 | 主机调用 | 可以省略 |
同时,核函数在编写时有以下常用的限制:
- 只能访问设备内存
- 返回类型只能为
void - 显示异步
错误处理
上文提到的CUDA API提供的函数的返回类型大多为cudaError_t,这也是枚举类型,可以直接%d打印出来,也可以将用cudaGetErrorString获得该错误码的详细信息
线程束
线程束分化
CUDA中指出C语言的控制流,这就会导致程序在不同的条件下执行不同的分支。一个线程束内由于获得的数据是不同的,可能执行到不同的逻辑分支,即“线程束分化”。然而SIMT使得每个指令周期内,线程束内的所有线程必须执行相同的指令。因此想要执行所有逻辑分支,只能花费额外的时钟周期,导致性能严重下降。
避免线程束分化导致的性能下降的根本思路是避免同一个线程束内的线程产生分化。这一思路能够成功实践的条件是我们上文介绍的threadId的计算方法。我们可以让threadId相邻的32个线程执行同一个分支,来避免线程束分化。
- Title: CUDA
- Author: OWPETER
- Created at : 2025-07-22 09:21:09
- Updated at : 2025-08-04 17:55:35
- Link: https://owpeter.github.io/2025/07/22/ML/CUDA/
- License: This work is licensed under CC BY-NC-SA 4.0.