# wget https://raw.githubusercontent.com/karpathy/char-rnn/master/data/tinyshakespeare/input.txt withopen('input.txt', 'r', encoding='utf-8') as f: text = f.read()
我们的模型使用的数据集是莎士比亚诗歌集合,其中包含了莎士比亚所有的诗,大小大约1M
为了防止模型过拟合,需要将数据集划分为训练集与验证集
1 2 3 4
data = torch.tensor(encode(text), dtype=torch.long) n = int(0.9*len(data)) # first 90% will be train, rest val train_data = data[:n] val_data = data[n:]
# here are all the unique characters that occur in this text chars = sorted(list(set(text))) vocab_size = len(chars) # create a mapping from characters to integers stoi = { ch:i for i,ch inenumerate(chars) } itos = { i:ch for i,ch inenumerate(chars) } encode = lambda s: [stoi[c] for c in s] # encoder: take a string, output a list of integers decode = lambda l: ''.join([itos[i] for i in l]) # decoder: take a list of integers, output a string
defget_batch(split): # generate a small batch of data of inputs x and targets y data = train_data if split == 'train'else val_data ix = torch.randint(len(data) - block_size, (batch_size,)) x = torch.stack([data[i:i+block_size] for i in ix]) y = torch.stack([data[i+1:i+block_size+1] for i in ix]) x, y = x.to(device), y.to(device) return x, y
def__init__(self, vocab_size): super().__init__() # each token directly reads off the logits for the next token from a lookup table self.token_embedding_table = nn.Embedding(vocab_size, vocab_size)
# idx and targets are both (B,T) tensor of integers logits = self.token_embedding_table(idx) # (B,T,C)
if targets isNone: loss = None else: B, T, C = logits.shape logits = logits.view(B*T, C) targets = targets.view(B*T) loss = F.cross_entropy(logits, targets)
这里最重要的是要理解logits张量各个维度代表的含义:B, Batch size,代表批次大小,指一次并行处理的样本数量;T, Time steps, 代表每个序列包含的token数量,也就是上下文长度;C, Channels,代表每个token嵌入向量的维度
另外,为什么要view一下,因为cross_entropy对于输入形状有要求:
最后编写推理函数。推理函数是在模型训练完成后,用来运行模型进行生成任务的函数
1 2 3 4 5 6 7 8 9 10 11 12 13 14
defgenerate(self, idx, max_new_tokens): # idx is (B, T) array of indices in the current context for _ inrange(max_new_tokens): # get the predictions logits, loss = self(idx) # focus only on the last time step logits = logits[:, -1, :] # becomes (B, C) # apply softmax to get probabilities probs = F.softmax(logits, dim=-1) # (B, C) # sample from the distribution idx_next = torch.multinomial(probs, num_samples=1) # (B, 1) # append sampled index to the running sequence idx = torch.cat((idx, idx_next), dim=1) # (B, T+1) return idx
model = BigramLanguageModel(vocab_size) m = model.to(device)
# create a PyTorch optimizer optimizer = torch.optim.AdamW(model.parameters(), lr=learning_rate)
foriterinrange(max_iters):
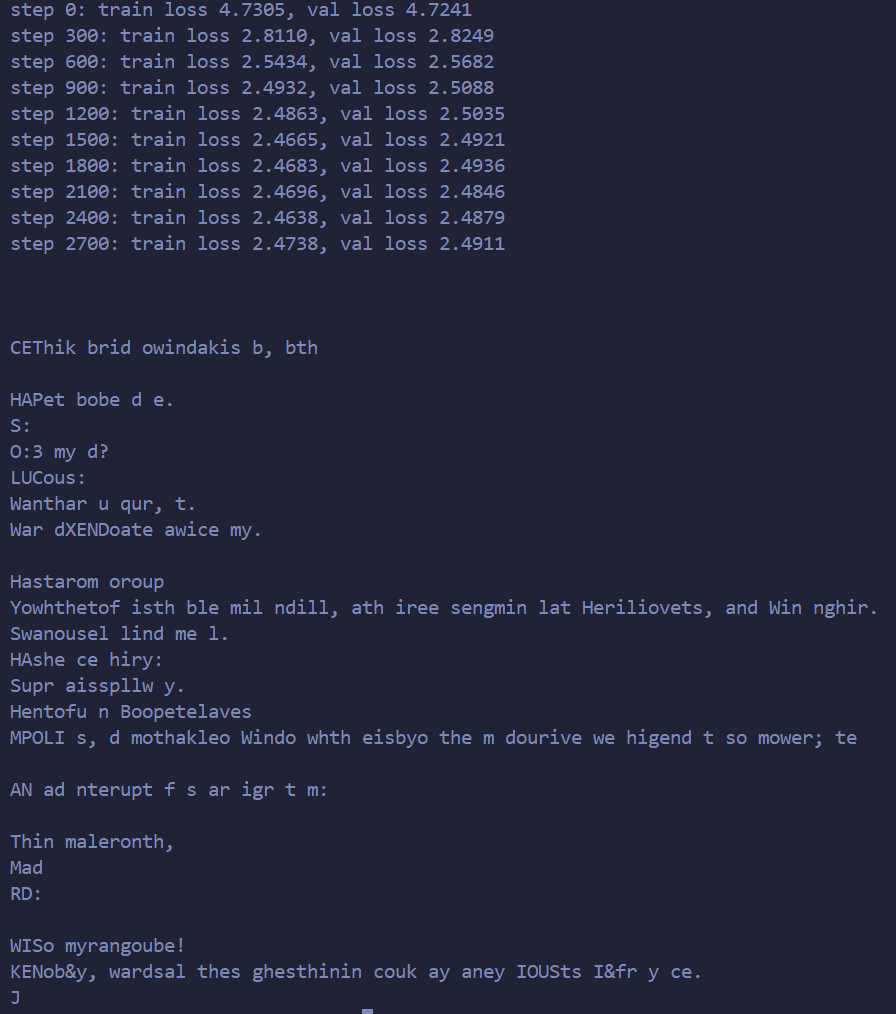
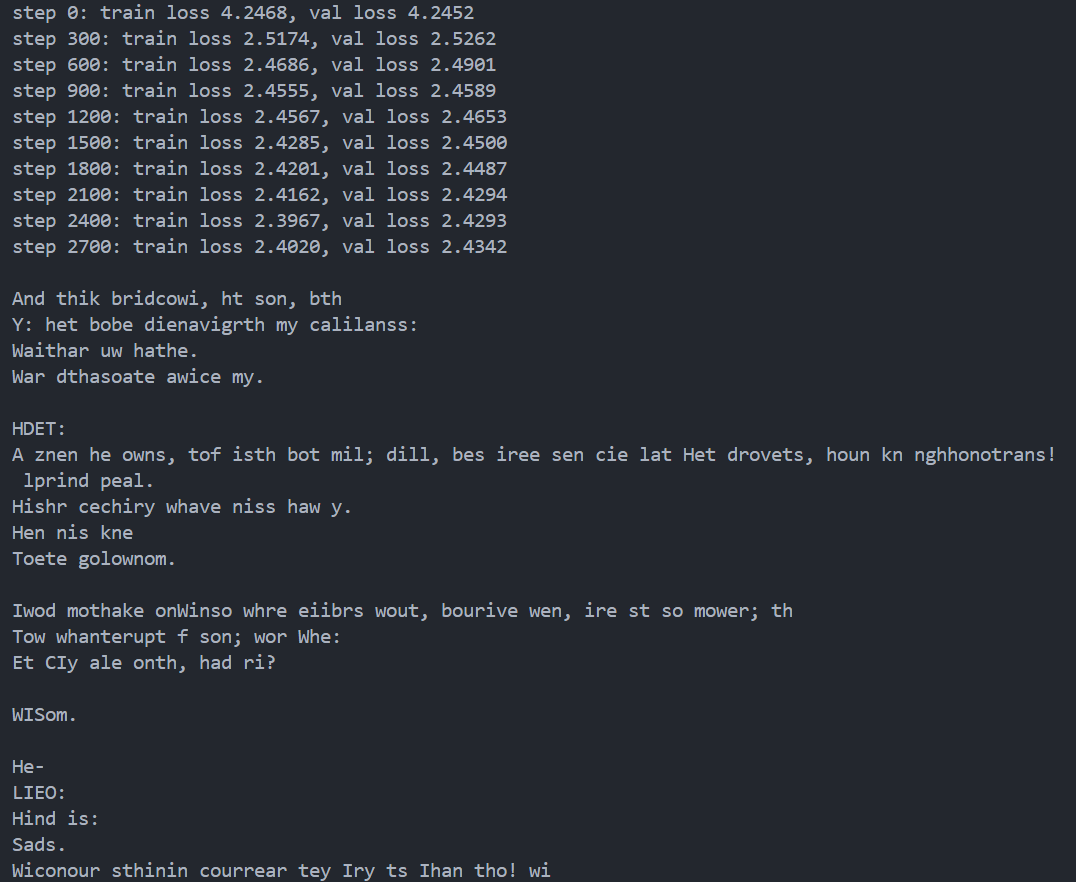
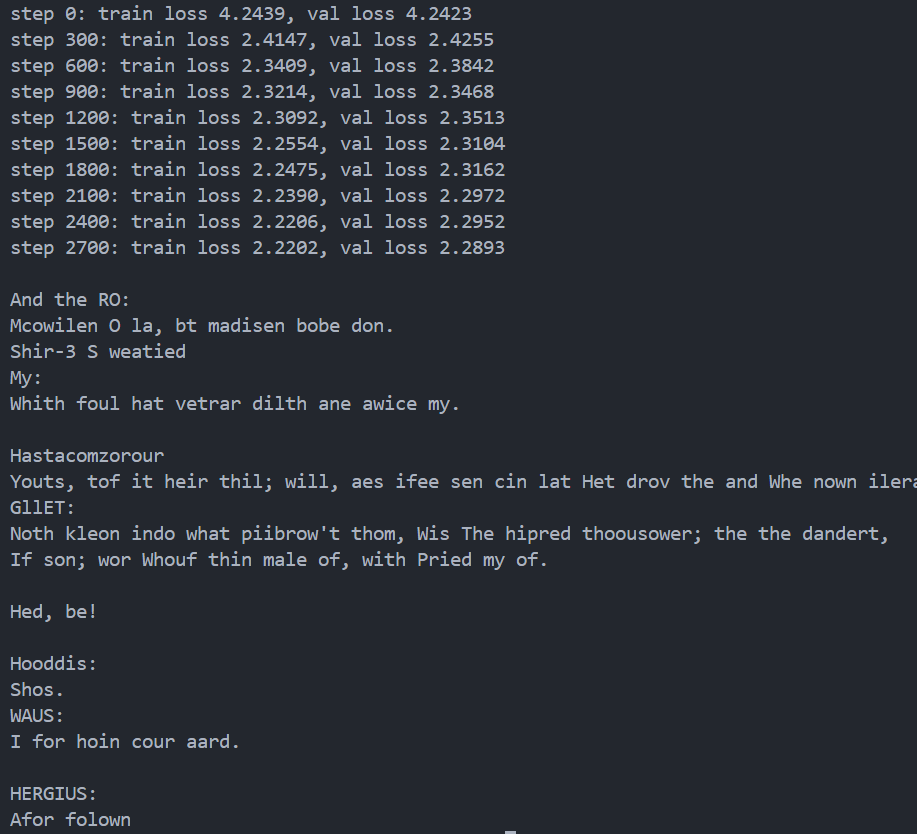
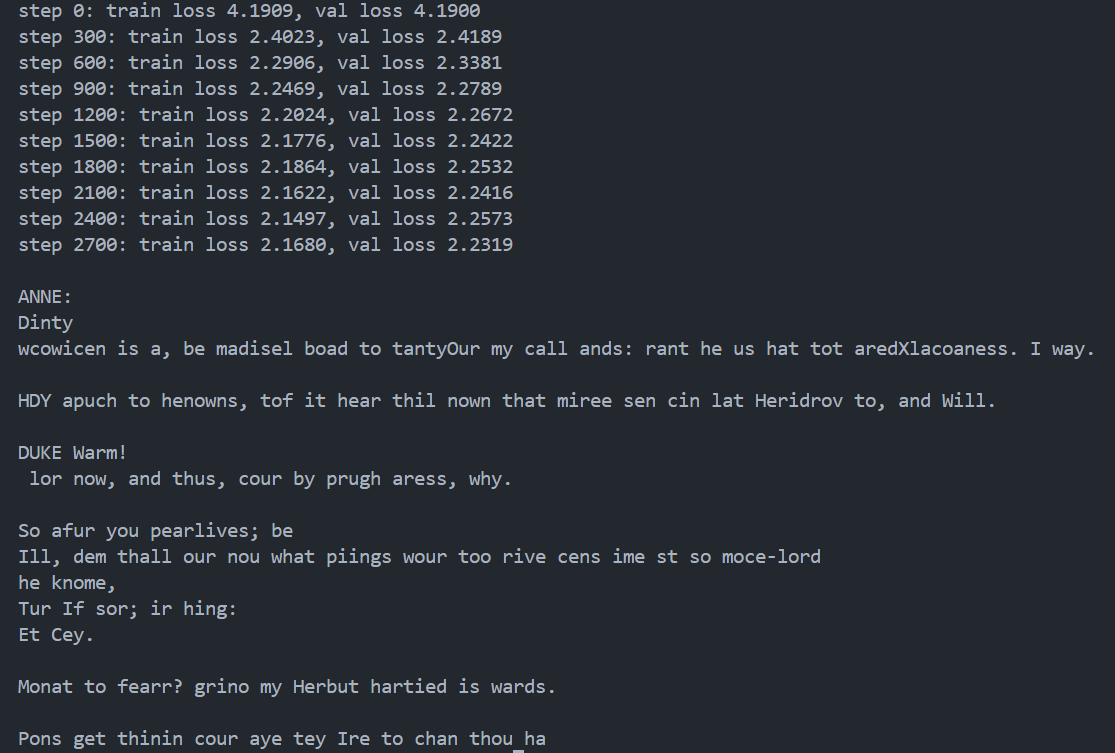
# every once in a while evaluate the loss on train and val sets ifiter % eval_interval == 0: losses = estimate_loss() print(f"step {iter}: train loss {losses['train']:.4f}, val loss {losses['val']:.4f}")
# sample a batch of data xb, yb = get_batch('train')
# evaluate the loss logits, loss = model(xb, yb) optimizer.zero_grad(set_to_none=True) loss.backward() optimizer.step()
# generate from the model context = torch.zeros((1, 1), dtype=torch.long, device=device) print(decode(m.generate(context, max_new_tokens=500)[0].tolist()))
First Servant: You tell might, Aufidius, in descending your and accordering to waiting: dost you to me, my chamber, and prologation again, and I drived think. Happine! E should how margar me hear to a custimar? Is By the time forber Saintman: but what I will she undo report; and there have threat of the please. Oposite, sir, here that pikes to the pude woo to flow last; and your knowers and loves; bear me heavenly as will commanded, as you will do.
QUEEN MARGARET: Read upon, and thou art come of them for the shepherds fall benefit.
Second MENERSE: Thou art done, and for three once, of thou art dove.; For any thing to mad, an oathless of rute, But thou first, to shrewdst which word-blood I spright, Upon the reason, fury, their deaths: iffiance, will I look that like triophet the weak, but chief, let their five blackles; from exclamation meet or than thou dost. To unachild, Have done in this day, and make thee out of mine; first's those our bosoms advance to yourselves; For thought yet too return back the state; and Be stand to please. For this indeeds have rofining and with love: As there, like one fall, to it scall.
现在已经有明确的角色划分了,格式完全是莎士比亚的格式,语言上也能看出来是英语了。
最后,可以通过以下代码查看这个小模型有多少参数:
1 2 3 4
# model = BigramLanguageModel(vocab_size) # m = model.to(device)
print(sum(p.numel() for p in m.parameters()) / 1e6, "M")